Date: Tue, 11 Jan 2022 13:51:51 -0500
I am running the mdinOPT.GPU benchmark on my 4 RTX3090 GPU system. It has
dual AMD CPUs each with 64 cores. The system also has 2TB of RAM.
The OS is RHEL 8 and Amber20 is compiled with CUDA kit 11.4.1 and OpenMPI
4.1.1 to give $AMBERHOME/bin/pmemd.cuda_SPFP.MPI
When I set export CUDA_VISIBLE_DEVICES=0,1,2 and run this command:
mpirun -np 3 $AMBERHOME/bin/pmemd.cuda_SPFP.MPI -i mdinOPT.GPU -o
JACOPT_3.out -p JAC.prmtop -c JAC.inpcrd
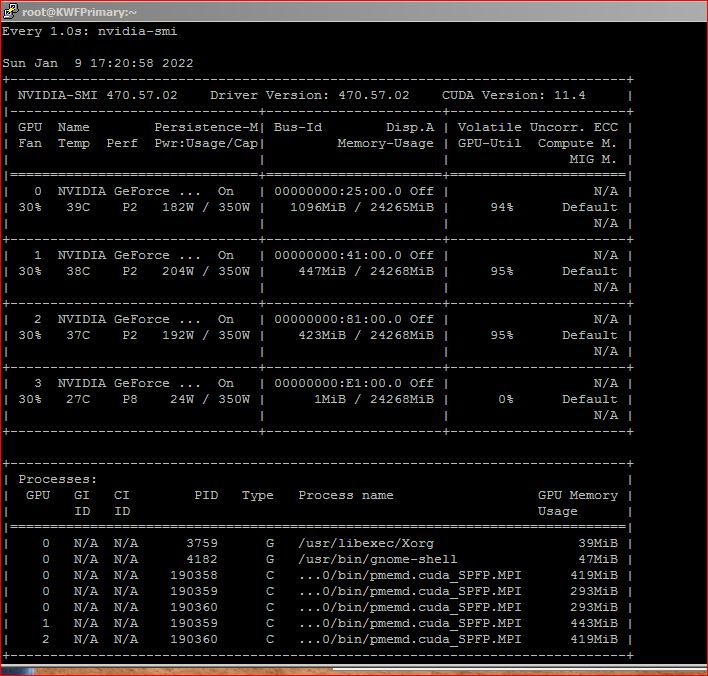
I observe in nvidia-smi that 3 processes are routed to GPU 0 with one
process routed to GPU 1 and another to GPU 2 for a total of 5 GPU processes.
See attached screen shot (if it clears the posting process).
Why are 3 processes being routed to GPU 0? I also tried the same command
after setting OMP_NUM_THREADS=1 but that made no difference. Neither did
mpirun --bind-to none -np 3 ...
This behavior is not observed when I set export CUDA_VISIBLE_DEVICES=0,1
and run this command:
mpirun -np 2 $AMBERHOME/bin/pmemd.cuda_SPFP.MPI -i mdinOPT.GPU -o
JACOPT_0_1.out -p JAC.prmtop -c JAC.inpcrd
or
export CUDA_VISIBLE_DEVICES=2,3
mpirun -np 2 $AMBERHOME/bin/pmemd.cuda_SPFP.MPI -i mdinOPT.GPU -o
JACOPT_2_3.out -p JAC.prmtop -c JAC.inpcrd
What I get there is 2 GPU processes on each GPU.
Is there something else I need to do to get only 1 process per GPU or is
this normal behavior?
Also note, the performance for the 2 GPU runs is ns/day = 1308.25 while
for the 3 GPU run it is ns/day = 606.08.
Any suggestions on what I am doing wrong and how to fix it?
Thanks.
Jim Kress
_______________________________________________
AMBER mailing list
AMBER.ambermd.org
http://lists.ambermd.org/mailman/listinfo/amber
(image/jpeg attachment: 3GPUSnipImage.JPG)
