Date: Wed, 17 Jan 2024 11:18:17 +0800
Note: For the replica MD jobs I submitted to older 8 * RTX 2080ti nodes,
normally I used 32~48 replicas in total. Each GPU equally takes 4~6
subjobs, not only one single. No more data-exchange GPU memory usage on
GPU0.
Zhenquan Hu <zhqhu.sioc.gmail.com> 于2024年1月17日周三 09:26写道:
> Dear all,
>
> Recently I tried to run multiple replica MD simulations with
> pmemd.cuda.MPI on a single machine with 4 GPU cards ( NVIDIA RTX A6000).
> There are 8 replicas in total. GPU1-3 cards each takes 2 jobs, which is
> normal. But GPU0 takes 8 jobs in total. 2 of them are the same as the other
> GPUs, but for the other 6 jobs each requires ~1/3 of GPU memory, these
> jobs seemed like for data exchange, because each of them has the same
> unique PID which could be found in GPU1-3 PIDs. As a result, GPU0 needs
> much more GPU memory for replica version MD simulations.
> I have tried this kind of MD simulations on some older machines (NVIDIA
> RTX 2080Ti, 8 GPU cards on a single node, CUDA 10.2), on which GPU0 took
> the same GPU memory compared with other GPUs, no memory usage for data
> exchaunge.
> Because the least supported CUDA version for RTX A6000 is CUDA 11, I tried
> with both CUDA 11.6 and CUDA 11.7, and also tried with another node with
> RTX 3080 which also needs CUDA 11 at least. All need quite a lot of GPU
> memory on GPU0 for data-exchange.
> I suppose it should be a multi-GPU bug as cpu core could not communicate
> with GPU1-3 directly but via GPU0 instead, am I right?
> Is there any way to solve this problem either from pmemd or NVIDIA?
>
> Best regards,
> Zhenquan Hu
>
> [image: gpuinfo02.png]
> [image: gpuinfo01.png]
>
_______________________________________________
AMBER mailing list
AMBER.ambermd.org
http://lists.ambermd.org/mailman/listinfo/amber
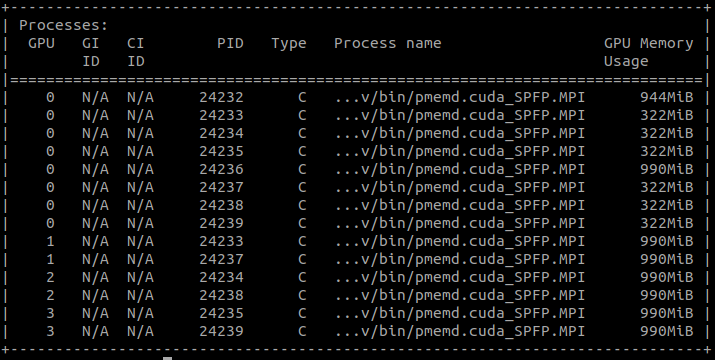
(image/png attachment: gpuinfo02.png)
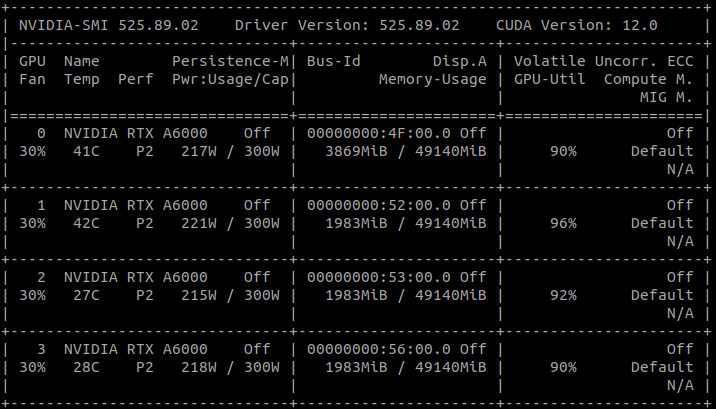
(image/png attachment: gpuinfo01.png)
